
Jump To Section
With the wave of Digital Transformation every business is trying to ride, how do you keep up with the wave of users that comes with it?
Online and self-serve systems have seen a massive rise with the growth of digital platforms, and an even bigger push with the COVID pandemic. These systems became the need of the hour to limit human interaction, and so technology evolved to a point where providing a seamless and swift digital experience became a standard.
But despite that, many corporations still can’t take full advantage of these new technologies and often end up losing potential customers simply because their legacy systems can’t keep up.
The Challenge of Adopting New Technologies For Large Enterprises
Due to a dependency on mission-critical legacy systems — predominantly owing to high replacement costs — enterprises are forced to build digital systems on top of the existing legacy systems. This results in two architecture layers with different service-level agreements (SLAs).
But while digital APIs deployed on the cloud can scale automatically to sustain any workload, these legacy systems would eventually crash under heavy load, causing loss of business opportunities.
In this article, we’re diving into a real-world application of the Command Query Responsibility Segregation (CQRS) design pattern and event sourcing to prevent this issue of overloaded legacy systems.
CQRS Pattern to the Rescue
Let’s dissect the problem stated in the previous section.
As we understand it more deeply, we find the root cause behind why use CQRS and event sourcing patterns: modern digital APIs have the ability to produce a much higher volume of transactions than legacy systems can support.
Can we have an architecture where the legacy system is required to process only a subset instead of all the transactions?
The CQRS software architecture pattern offers a good solution.
What is CQRS?
The command query responsibility segregation in the CQRS architecture separates the write and read transactions in such a way that digital APIs can commit to one system and query from another.
The diagram below shows what is the CQRS pattern and how it changes the architecture to send a subset of transactions, “write actions”, which usually represent a tiny portion of all the transactions generated by a digital system.
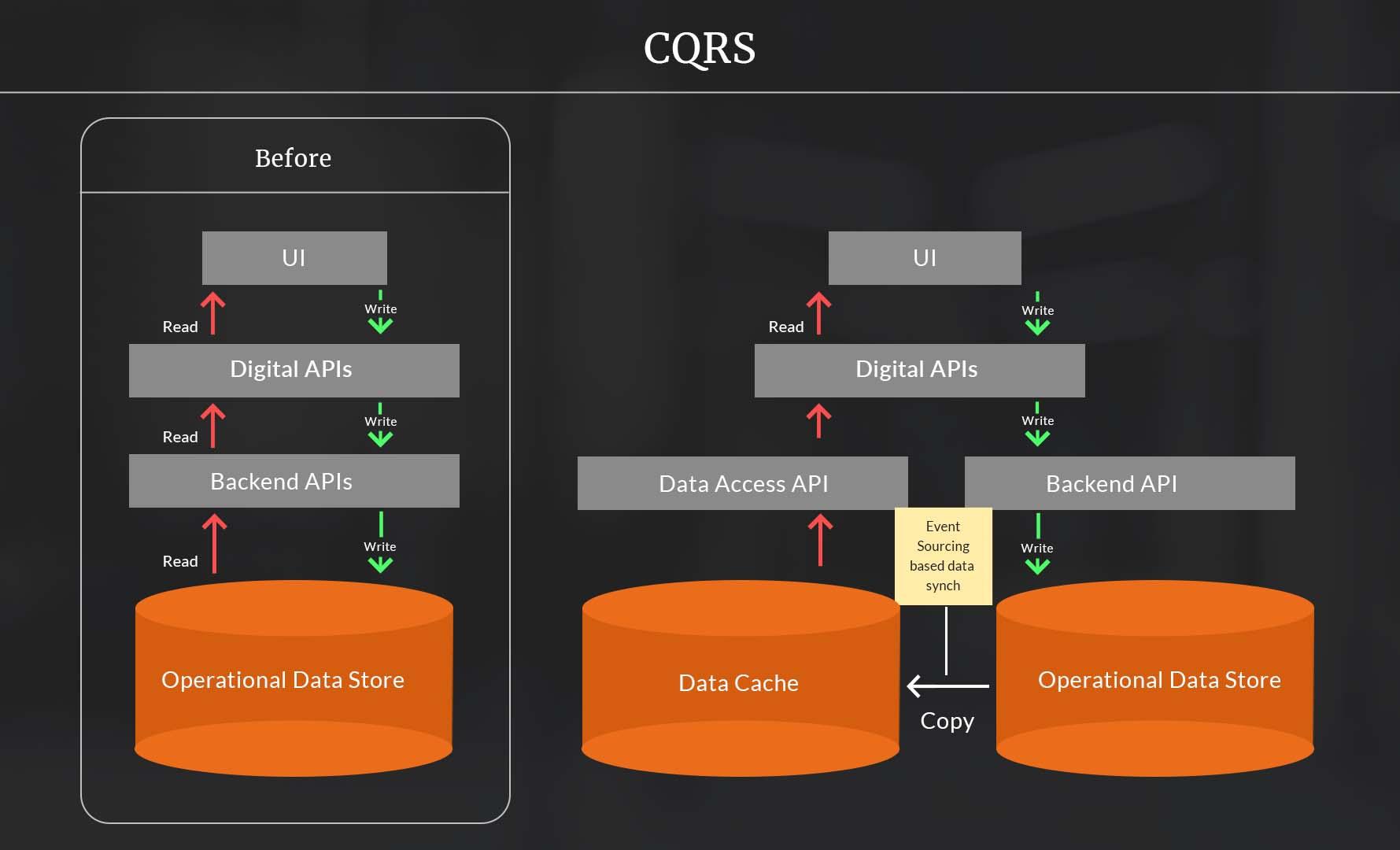
Usually, the CQRS pattern is coupled with event sourcing patterns that facilitate data synchronization between the source operational data store and the target read-only data cache in near real-time.
The data cache is a high performing database that is located close to the digital APIs to reduce latency. The data model is designed to maximize read performance instead of data integrity since this is a read-only data store.
Once the changes above have been implemented, we notice a huge performance increase in the read transaction. We can also observe that the backend systems were able to cope with the seasonal spikes in volume.
Implementation Strategy for the CQRS Pattern
Given the complexity of the CQRS design pattern, it is preferable to implement it in phases, focusing on the most critical APIs first.
When we were using the CQRS pattern, my team had an urgency to fix the issue completely. Hence, the phased approach was rolled out.
We’ve realized it works well, and using it for every single API that the digital systems use is found to deliver a reliable experience.
But as with any new technology, there can be challenges with the implementation of the CQRS pattern.
Two Challenges with CQRS Pattern Implementation
The CQRS pattern has its benefits, but it also comes with many challenges that we need to take into consideration before making a decision to implement it.
The two biggest challenges we faced while implementing command query responsibility segregation with event sourcing pertained to:
- Testing
- Race Conditions
Challenge #1: Testing CQRS Pattern
The CQRS pattern impacts the most valuable corporate asset in the digital world: customer data.
Any defects that are not detected and fixed in a non-production environment may have a drastic impact on customers. For instance, a CQRS defect can result in a privacy issue where a customer gets access to some other customer data.
In order to avoid such issues, testing in non-production environments alone is not sufficient.
For our project, we went with the traditional approach of testing in non-production and allowing for a period of business readiness testing in production. Then, we launched the system to the customers.
As a result, there were many corner cases and special data that we never accounted for that caused some serious issues in production.
Solution:
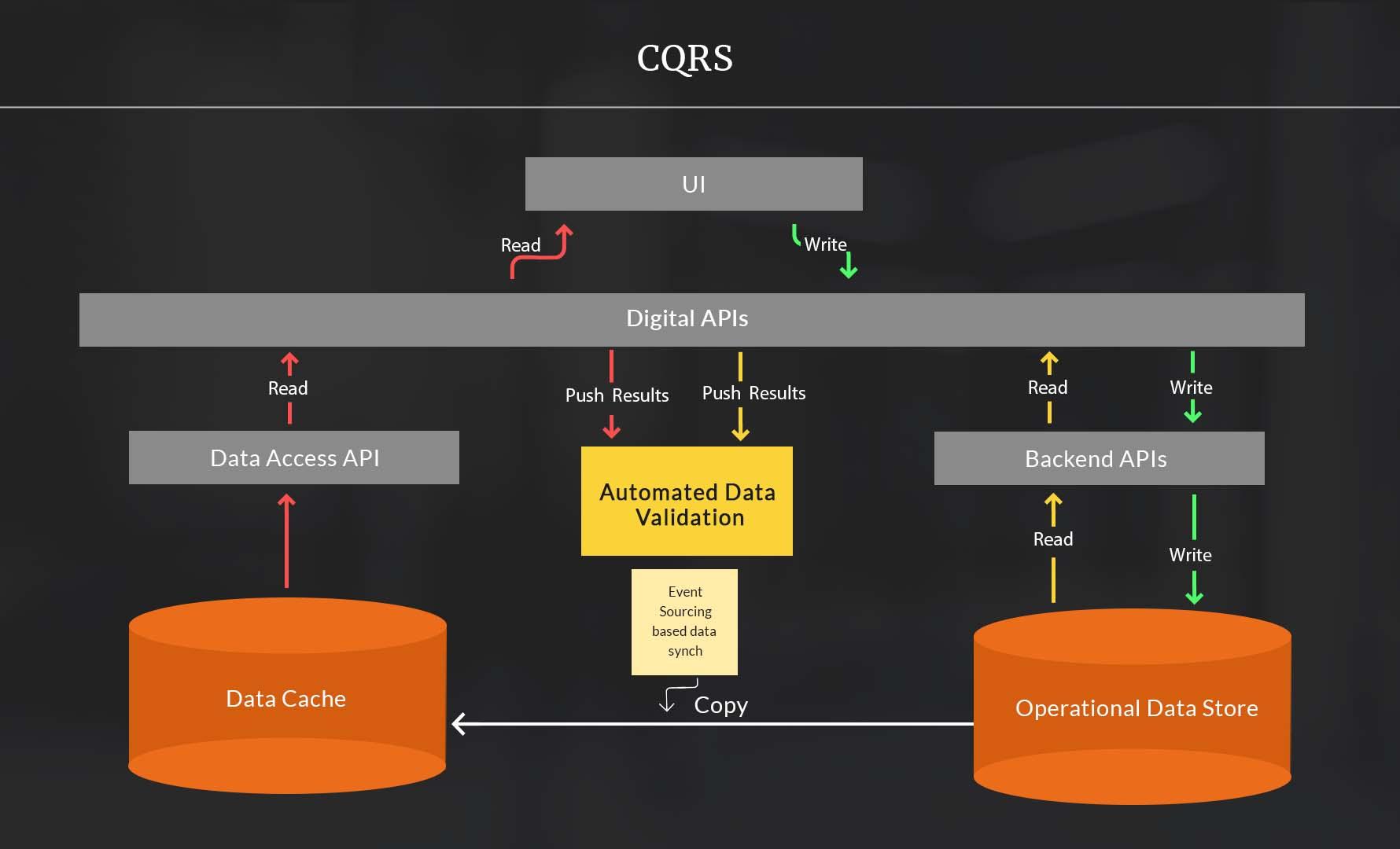
A better approach would have been to run the old and new system side by side for some period of time and automatically validate the output from both systems for the same requests in production. The diagram below outlines this approach.
Challenge #2: Race conditions
The operational data store is the source of truth and is updated by many systems, amongst which is the digital system itself.
When the update happens from the digital system, the customer expects the new information to reflect on all the views immediately.
With the CQRS implementation, this may not be feasible since there could be a delay in updating the data cache and hence the digital APIs would still read the old data.
Solution:
To get around this race condition, the write transactions that are initiated from the digital system had to also mark the data in the cache as stale and save parts of the write transaction response that can be used for temporarily presenting the latest version of the data on the user interface.
Takeaway
Despite the challenges that came with it, when we implemented the CQRS pattern, the benefits were evident:
- An enhanced user experience
- An increased system availability during the transaction spike period
However, with that said, the CQRS pattern is still relatively nascent.
While it may seem to be a disruptive solution for a very pressing issue in legacy-based systems, implementing the CQRS pattern should always be taken on a case-by-case basis and with preparedness for the challenges that could arise with it.
FAQs
Is GraphQL a CQRS?
CQRS is a design pattern used in programming that treats data in queries and commands separately. While GraphQL also defines input and output object types separately, aligning with the concepts of CQRS design patterns, CQRS GraphQL is a query language that standardizes data queries.
Is CQRS an architecture or pattern?
CQRS is a design pattern that can be applied in software architecture. It is a CQRS architectural pattern that separates commands and queries in the application architecture.
What is the difference between CQRS and event sourcing?
The implementation of CQRS happens through a segregation of commands and queries. On the other hand, for implementing event sourcing, the sequence of the events is used to track any changes in data. Event sourcing is a practice to store domain events.
How do you implement CQRS?
The implementation of CQRS lies in the segregation of commands and queries, meaning it is executed using separate models for read and write. In addition to the how, it’s important to know when to use CQRS. It’s best to implement CQRS in phases and coupled with event sourcing patterns.



